https://www.acmicpc.net/problem/1181
1181번: 단어 정렬
첫째 줄에 단어의 개수 N이 주어진다. (1 ≤ N ≤ 20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
www.acmicpc.net
1. 입력할 때 공백 부분(\n) 리스트에 빼고 넣기
# 공백 있는 문자열
name = " B l o ck DM a s k "
# 양쪽 공백 제거
result1 = name.strip()
# 왼쪽 공백 제거
result2 = name.lstrip()
# 오른쪽 공백 제거
result3 = name.rstrip()
print(f"name : |{name}|")
print(f"name.strip() : |{result1}|")
print(f"name.lstrip() : |{result2}|")
print(f"name.rstrip() : |{result3}|")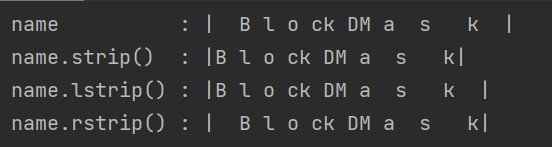
각각 왼쪽 공백, 오른쪽 공백, 전체 공백 없애기
# 입력
n = int(input())
words = []
for _ in range(n):
word = list(sys.stdin.readline().strip())
words.append(word)
2. 알파벳 순서대로 맞추기 - ord() 사용: ASCII 코드 번호 알려줌
def whenSameLength(j, words):
# 같은 단어는 삭제해주기
if words[j - 1] == words[j]:
words.remove(words[j])
else:
for k in range(len(words[j])):
# b > a 일 때 자리 바꾸기 (ascii 코드 숫자 소환)
if ord(words[j - 1][k]) > ord(words[j][k]):
temp = words[j - 1]
words[j - 1] = words[j]
words[j] = temp
break
elif ord(words[j - 1][k]) == ord(words[j][k]):
# 같을 때는 다음 알파벳으로 넘어가기
continue
else: # a < b 일 때는 자리 그대로 두고 끝내기
break
[파이썬] Python 아스키코드(ASCII) 변환 방법(ord(), chr(), hex()) 및 아스키코드표 - NARAGARA
아스키코드(ASCII)란? 미국정보교환표준부호(영어: American Standard Code for Information Interchange), 또는 줄여서 ASCII(/ˈæski/,아스키)는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다. 아스키는 컴퓨
www.naragara.com
3. 마지막에 리스트에 있는 각각의 원소를 붙여서 출력하기

O(N^2)으로 아래와 같이 정렬 했더니 시간 초과가 나왔다.
# BOJ_1181
import sys
# 입력
n = int(input())
words = []
for _ in range(n):
word = list(sys.stdin.readline().strip())
words.append(word)
def whenSameLength(j, words):
# 같은 단어는 삭제해주기
if words[j - 1] == words[j]:
words.remove(words[j])
else:
for k in range(len(words[j])):
# b > a 일 때 자리 바꾸기 (ascii 코드 숫자 소환)
if ord(words[j - 1][k]) > ord(words[j][k]):
temp = words[j - 1]
words[j - 1] = words[j]
words[j] = temp
break
elif ord(words[j - 1][k]) == ord(words[j][k]):
# 같을 때는 다음 알파벳으로 넘어가기
continue
else: # a < b 일 때는 자리 그대로 두고 끝내기
break
# 길이가 짧은 것부터 나열하기
for i in range(len(words) - 1):
m = len(words) - i
for j in range(1, m):
# 단어 길이가 다를 때
if len(words[j - 1]) > len(words[j]):
temp = words[j - 1]
words[j - 1] = words[j]
words[j] = temp
# 단어 길이가 같을 때
elif len(words[j - 1]) == len(words[j]):
whenSameLength(j, words)
for word in words:
print(''.join(word))
질문 게시판을 보니 O(NlogN) 으로 퀵정렬 하라는 데 라이브러리를 쓰거나 직접 구현해서 바꿔봐야겠다.
sort() 자체가
퀵정렬O(NlogN)으로 동작한다고 한다.
따라서 아래와 같이 3가지 순서대로 정렬해주었다.
set은 turple 형태로 중복을 제거해주고, 정렬은 set다음에 하는 것이 좋다.
1. 중복 제거 - set
2. 알파벳 순서대로 정렬 - sort()
3. 길이로 정렬 - sort( key=len )
# BOJ_1181
import sys
# 입력
n = int(input())
words = []
for _ in range(n):
word = list(sys.stdin.readline().strip())
words.append(word)
# 1. 중복 제거
words = list(set(map(tuple, words)))
# 알파벳 순서로 정렬
words.sort()
# 3. 길이로 정렬
words.sort(key=len)
for word in words:
print(''.join(word))

'Computer Science > Algorithm' 카테고리의 다른 글
| [백준] 1676번 팩토리얼 0의 개수 (0) | 2023.01.12 |
|---|---|
| [백준] 1764번 듣보잡, 시간초과 (0) | 2023.01.11 |
| [백준] 10828번 스택 구현 - 시간초과문제 (0) | 2023.01.08 |
| [백준] 2108번 통계학, 중앙값: 인덱스 조심(반올림 말고 내림) (0) | 2023.01.07 |
| [백준] 1929번 소수 구하기, 실버3, python (0) | 2023.01.07 |


